

On December 20, 2024, OpenAI's o3 system scored 85% on the ARC-AGI benchmark test, significantly higher than the previous AI's best result (55%) and equivalent to average human results. o3 also performed well on a very difficult math test.
[Article issu de The Conversation, écrit par Michael Timothy Bennett, PhD Student, School of Computing, Australian National University et Elija Perrier, Research Fellow, Stanford Center for Responsible Quantum Technology, Stanford University]
Creating “general” artificial intelligence is the stated goal of all major AI research laboratories. OpenAI's recent announcement seems to indicate that the company has just accomplished a feat in this direction. (ndlt: The French abbreviation for “artificial general intelligence” is “IAG” but this acronym is sometimes used to talk about generative artificial intelligence, which is a particular family of artificial intelligence systems, exploiting in particular deep learning, and of which ChatGPT is the most media member.)
Even if a certain skepticism is in order, many AI researchers and developers have the feeling that the lines are moving: the possibility of artificial general intelligence seems more tangible, more current than they thought. so far. What about it? Let's try to decipher this announcement.
Generalization and artificial intelligence
To understand what the result obtained by o3 from OpenAI means, we need to look at the nature of the ARC-AGI test that o3 passed.
This is a test evaluating the “sample efficiency” of an AI system (ndlt: sometimes translated as “data efficiency”), that is to say its ability to adapt to a new situation, or, in more technical terms, the ability of a machine learning model to obtain good performance with learning based on little data.
This is because training these models is normally based on very large datasets, making them expensive to train. An AI system like ChatGPT (GPT-4) is not very “data efficient”: it was trained on millions of examples of human text, from which it derived probabilistic rules that dictate the most probable sequences of words. This method is effective for generating general texts or other “common” tasks; but in the case of uncommon or more specialized tasks, the system is less efficient because it has little data for each of these tasks.

Until AI systems can learn from a small number of examples (from a small data set) — that is, demonstrate some “data efficiency” — they will not will not be able to adapt to rarer situations, they will only be used for very repetitive tasks and those for which occasional failure is tolerable.
The ability to accurately solve unknown or new problems based on little data is called “generalization ability.” It is considered a necessary, even fundamental, element of intelligence.
Grids and patterns
This is why the ARC-AGI benchmark test, which assesses “general” intelligence, uses small grid problems like the one presented below. From a very limited number of examples, the person or AI being tested must find the model that transforms the left grid into the right grid. It is “data efficiency” that is evaluated here.
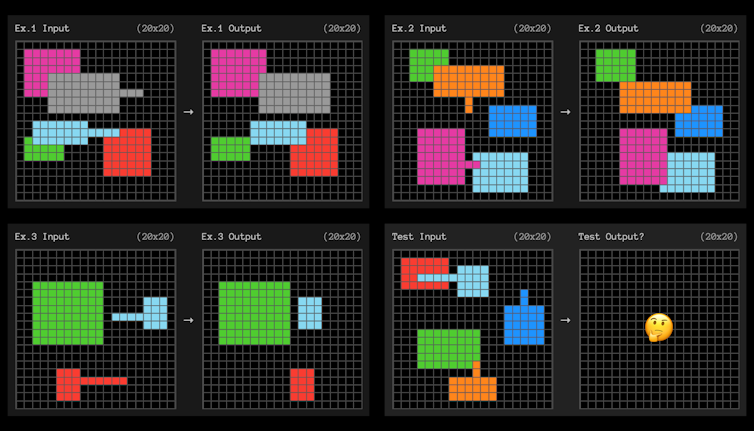
Each exercise begins by providing three examples, from which rules must be extracted, which “generalize” the three examples… and allow the fourth to be solved.
This is a lot like IQ tests.
Find the necessary and sufficient rules to adapt
We don't know exactly how OpenAI did this, but the test results themselves suggest that the o3 model is very adaptable: from just a few examples, it found generalizable rules that allowed it to solve the exercises.
To tackle this type of exercise, you must find the necessary and sufficient rules to resolve the exercise, but not impose additional rules on yourself, which would be both useless and restrictive. We can demonstrate mathematically that these minimal rules are the key to maximizing one's ability to adapt to new situations.
What do we mean by “minimum rules”? The technical definition is complicated, but the minimum rules are generally those that can be described in simpler statements.
In the example above, the rule could be expressed as: “Any shape with a protruding line will move to the end of that line and cover any other shapes it overlaps with in its new position.”
Looking for chains of thought?
While we don't yet know how OpenAI achieved this, it seems unlikely that engineers deliberately optimized the o3 system to find minimal rules — but o3 must have found those rules.
We know that OpenAI started with their generic version of the o3 model (which differs from most other large language models because it can spend more time “thinking” about difficult questions) and then trained it specifically to take the ARC-AGI test.
French AI researcher François Chollet, who designed the benchmark test (editor's note: and who worked at Google until recently), believes that o3 looks for different “chains of thought” describing the steps to follow to solve the task. (Editor’s note: A “chain of thought” is a strategy exploited in AI, which mimics a human strategy consisting of breaking down a complex problem into small, simpler units, leading step by step to a global solution.)
o3 would then choose the “best” chain of thought based on a rule defined in a relatively pragmatic and vague way, in a “heuristic” approach.
This strategy would not be very different from that used by Google's AlphaGo system to search for different possible sequences of movements capable of beating the world go champion in 2016.

We can think of these chains of thought as programs that are adapted to the examples and allow us to solve them. Of course, if o3 does indeed exploit a method similar to that used in AlphaGo, it was necessary to provide o3 with a heuristic, or soft rule, to allow it to determine which program was the best. Because thousands of different programs, each apparently as valid as the other, could be generated to try to solve the three examples. We could imagine a heuristic which “selects the minimal program” or which “selects the simplest program”.
However, if it's an AlphaGo-like mechanism, just ask an AI to create a heuristic. This is what happened for AlphaGo: Google trained a model to rate different sequences of movements as better or worse than others.
What we still don't know
The question that therefore arises is the following: are we really closer to artificial general intelligence? If o3 works as just described, the underlying model may not perform much better than previous models.
The concepts that the model learns from textual data (or more generally from human language) may not be more generalizable than before. Instead, we might simply be in the presence of a more generalizable “chain of thought,” discovered through the additional steps of training a specialized heuristic for the test in question today.
We will see more clearly, as always, with more perspective and experience around o3.
Indeed, almost nothing is known about this system: OpenAI has made fairly limited media presentations, and the first tests have been reserved for a handful of researchers, laboratories and institutions specializing in AI security .
Assessing o3's true potential will require extensive work, including determining how often it fails and succeeds.
Only when o3 is actually released to the public will we know if he's anywhere near as adaptable as an average human.
If so, it could have a huge and revolutionary economic impact, and usher in a new era of artificial intelligence capable of self-improvement. We will need new criteria for evaluating artificial general intelligence itself, and serious thinking about how it should be governed.
If not, o3 and its ARC-AGI test score will remain an impressive result, but our daily lives will remain much the same.
![]()

With an unwavering passion for local news, Christopher leads our editorial team with integrity and dedication. With over 20 years’ experience, he is the backbone of Wouldsayso, ensuring that we stay true to our mission to inform.


